
Het analytics ecosysteem is gebaseerd op het logisch data warehouse concept en gaat uit van een geintegreerde gegevensaanpak, waarbij vier belangrijke componenten samen de nieuwe referentie architectuur voor enterprise business intelligence vormen. Big data is niet anders dan business intelligence (bi), maar wel een moderne vorm ervan, waarbij meer en vooral andere datatypen het bestaande data warehouse completeren: een combinatie van data discovery, Hadoop en bi.
In mijn rol als enterprise data warehouse en big data solution architect heb ik vaak te maken met vraagstukken omtrent de integratie van big data met bestaande enterprise data warehouses. Veel van mijn klanten lanceren kleine big data-projecten, geïsoleerd van bestaande bi en data warehouse initiatieven. De scope van een dergelijk project behelst dan bijvoorbeeld web log data om het gedrag van klanten op de website te kunnen analyseren, tekstbestanden vanuit sociale media, gespreksnotities om sentiment te ontdekken of de laatste trend, sensor data gegenereerd door producten zoals tandenborstels, slimme lampen, thermostaten, auto’s of winkelwagentjes door een data mining algoritme te halen. Gegevens worden op een Hadoop cluster geplaatst dat tevens gebruikt wordt om het grote data warehouse af te romen van zogenaamde ‘koude – weinig geraadpleegde – data’ (data warehouse augmentation).
Naar mijn mening zijn de drijfveren van dergelijke initiatieven te vaak alleen kostenbesparingen, te lokaal en met een onduidelijke total value creation. Naast optimaliseren van het data warehouse, zijn voorbeelden hiervanhet analyseren van weblog data bestanden om het online klantgedrag beter te begrijpen of van sensor-gegevens van apparaten die lichaamsfuncties meten (‘the quantified self’). Dit zijn allemaal prima initiatieven. Naar mijn mening worden echter deze projecten nog te veel vanuit een applicatiegedachte opgezet en niet gedreven vanuit een centrale informatie architectuur. Het is essentieel data centric te werken waarbij het gebruik van de data centraal staat, niet alleen het volume of het formaat.
Daarbij zijn er eigenlijk grofweg drie typen data:
Ruwe data van bekende of (nog) onbekende structuur, direct vanuit de bron (website, sensor, transactiesysteem), die nog gefilterd of bewerkt moet worden. Dit kunnen zeer grote hoeveelheden gegevens zijn.
Research data ten behoeve van verder exploratie (self-service en data discovery), met zodanige structuur aangebracht dat analysetools en modellen met deze data om kunnen gaan. Deze gegevens hebben een beperkte houdbaarheid uit het oogpunt van relevantie.
Data met een productiestatus, gegevens die gegarandeerd zijn, van hoge kwaliteit, voldoen aan sla’s, waarvan de beveiliging gewaarborgd is en een hoge mate van beschikbaarheid kennen. Deze gegevens worden liefst meerder jaren bewaard.
Het is duidelijk dat het traditionele data warehouse in de vorm van een relationele data warehouse nog steeds een belangrijke rol speelt voor gegevens met een productiestatus, maar niet het enige platform kan zijn om de totale gewenste functionaliteit, volumes, variëteit in structuur en ook de snelheid waarmee gegevens aangevoerd worden, te kunnen afdekken.
Tekst
Bewust zeg ik niet ‘ongestructureerde data’. Naast het woord ‘big data’ is ‘ongestructureerd’ het meest verkeerd gebruikte woord in het business intelligence-vakgebied waar big data naar mijn mening gewoon een onderdeel van is. De laatste tien jaar is het aantal formaten en data structuren die geanalyseerd kunnen worden, enorm toegenomen. Tekst bijvoorbeeld, is een van de meest gestructureerde vormen van data met een formele syntax en grammatica. Echter pas sinds een aantal jaren zijn we in staat data in de vorm van tekst te kunnen analyseren: op basis van steekwoorden, kan men een idee van het sentiment in de tekst (bijvoorbeeld een gespreksverslag of blog post) krijgen en over meerdere talen heen aggregeren.
Er zijn nog maar weinig tools die in staat zijn het sentiment correct te analyseren door eerst de context te begrijpen. Zelfs een foto heeft (EXIF) metadata die gebruikt kan worden om een beter beeld van de klant te krijgen. Er zijn zelfs al tools die op basis van een analyse van het beeld zelf, een uitspraak kunnen doen over om wat voor type foto het gaat (actie, vakantie, natuur, mensen, et cetera). Dit is erg interessante informatie ter verrijking van het klantbeeld. Door deze toename van analyse-mogelijkheden en de technologische vooruitgang van mobiele en sensortechnologie is tevens de noodzaak ontstaan om al deze gegevens op een kostenefficiënte manier op te slaan en toegankelijk te maken.
Structuren combineren
Het gaat inderdaad om verrijking of de combinatie van de diverse typen gegevens. Data uit het centrale data warehouse bevat informatie over omzet, klachten, campagnes, voorraden, orders, facturen, grootboek, medewerkers. Allemaal zeer gestructureerde gegevens met relaties die aan hoge eisen moeten voldoen. Dit is het domein van het relationele data warehouse die overigens tegenwoordig prima in staat zijn zeer grote en soms ook minder bekende structuren zoals JSON op te slaan. Het is van essentieel belang ‘big data’ structuren te kunnen combineren met deze sterk geïntegreerde gegevens. Dit geldt zowel voor standaard of ad-hoc rapportage en enterprise dashboards als voor geavanceerde analyse op basis van voorspellende modellen door analisten en ‘data scientists’. Denk bijvoorbeeld aan:
– Combinatie van informatie over klantwaarde en klachten met navigatiegedrag op een online winkel en posts op een sociaal netwerk. Het kan efficiënter, (goedkoper, sneller) zijn om alleen van waardevolle klanten de vaste gegevens te koppelen met de gegevens van social listening tools en clickstream analyses.
– Combinatie van temperatuurgegevens van melk opgehaald bij boeren, de logistieke gegevens van melkwagens en klachten over bepaalde zuivelproducten. De oorzaak van de klachten kan heel goed erg lokaal zijn en veroorzaakt worden door suboptimale route of een defecte koeling in de melkwagen.
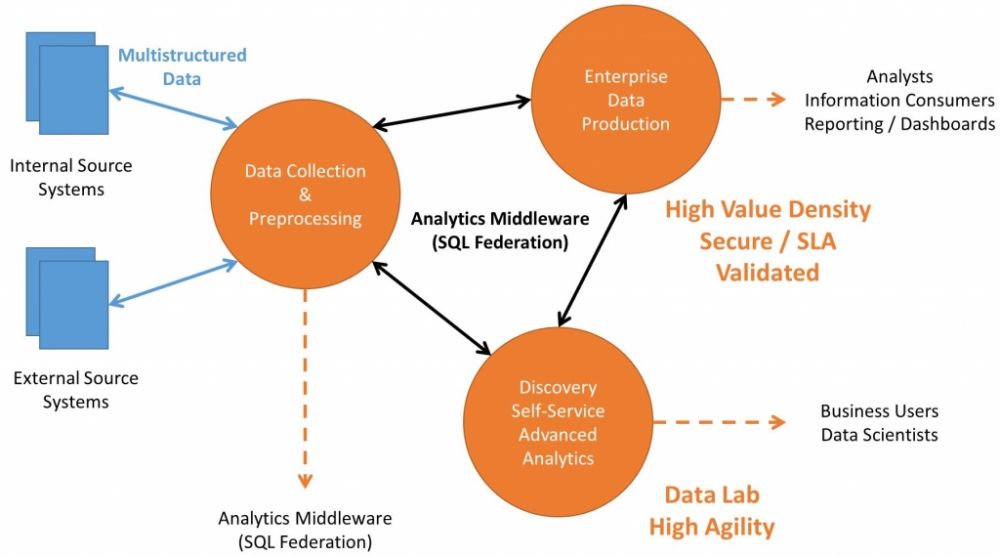
Ik wil pleiten voor een analytisch ecosysteem bestaande uit vier logische componenten. Iedere component kan bestaan uit één of meerdere fysieke entiteiten:
- Enterprise data warehouse (een combinatie van relationele, columnar en in-memory technieken)
- Discovery en self-service platform (speciaal ten behoeve van voorspellende analyses op basis van meestal een combinatie van wiskundige modellen, denk aan simulatiemodellen, clustertechnieken, graph-databases, tijdanalyse en met name gedragsanalyse op basis van een reeks events). Het moet mogelijk zijn zowel relationele als minder bekende structuren aan te kunnen die bijvoorbeeld op een Hadoop platform zijn opgeslagen. Dit is typisch een lab-omgeving.
- Data-opslag en pre-processing. Dit is bijvoorbeeld een Hadoop cluster of een minder geavanceerde relationele database, waar alle ruwe brongegevens opgeslagen en voorbewerkt worden.
- Analytische ‘middleware’. Dit is de belangrijkste component en wordt ook wel Federated Enterprise SQL (door met name Forrester) genoemd. Dit is een software framework dat er voor zorgt dat de drie componenten uit het analytische ecosysteem hun gegevens (met diverse structuren) eenvoudig met elkaar kunnen uitwisselen, zonder zware integratie etl-processen te schrijven, niet te verwarren met data virtualisatie tools. De analytische middleware is specifiek bedoeld voor een analytisch ecosysteem. Een voorbeeld is het dynamisch aanpassen van een queryplan op basis van de performance van het Hadoop-cluster. De oorspronkelijke query is geïnitieerd vanuit de relationele database maar haalt de online gearchiveerde data op uit Hadoop, transparant voor de gebruiker.
Het analytisch ecosysteem wordt door Gartner ook wel het ‘logical data warehouse’ genoemd en een aantal bekende leveranciers heeft reeds concrete oplossingen. Dit zal de nieuwe referentiearchitectuur zijn voor enterprise business intelligence. Gelukkig is de hype big data zo goed als voorbij en zien steeds meer bedrijven in dat het nog steeds gaat om het ondersteunen van de business door middel van informatie: het is nog steeds gewoon business intelligence.









Ik trek even de wenkbrauwen op bij dit commerciële epistel waarbij ik al snel de interesse en rode draad een beetje kwijt ben. Ietwat gechargeerd wellicht maar toch.
Statische data
Statische data zoals meetgegevens, in en verkoop gegevens, geverifieerde registratie gegevens of geverifieerde data van overheden. Deze Statische data blijkt tot 15% onjuist, onvolledig, corrupt. Ik lees daar niets van terug.
Dynamische data
Dit type data, lees de rest van alle data, is tot 50% corrupt.
Drie eenvoudige voordelen.
Wikipedia
Daar kunnen mensen zelf een ‘boompje’ opzetten die volgens een paar goeroe personen wordt gecontroleerd en geverifieerd en naar believen wordt afgewezen. Niet om iets te stellen maar als voorbeeld heeft ondergetekende van eigen systeem er eens een blad gemaakt die werd afgewezen omdat dit ‘commercieel’ van karakter zou blijken. Goede constructieve communicatie met dergelijke mensen blijkt niet nodig maar de grote gevestigde commerciële namen, die u zelf wel kunt bedenken, worden met naam faam en historie vermeld op…. wikipedia.
Er vanuit gaande dat mijn ‘casus’ beslist niet de enige is kan een bron als wikipedia moeilijk als ‘volkomen’ worden genomen en/of gezien.
Cookies
Heel veel data wordt geëxtraheerd door gebruik te maken van cookies. Persoonlijk, met mij velen, ben ik absoluut niet gecharmeerd van die cookies dus worden deze bij afsluiten van mijn browser weggegooid en dat gebeurt dus bij velen. Extractie van dergelijke data is dus niet te verifiëren of te bestempelen als compleet of correct maar leid tot corrupte BigData
Criminaliteit
De digitale criminaliteit heeft een enorme vlucht genomen en veroorzaakt in eerste en tweede aanleg een aanzienlijke schade en data vervuiling en genereert dus… heel vaak onjuiste, incomplete of corrupte data.
Dan hebben wij het maar even nog niet over het persoonlijk gebruik van de sociale media zoals linkedin waar menig er een beetje op los kan jokkebrokken zonder dat dit in eniger mate op eerste gezicht verifieerbaar is.
Al eerder bracht ik naar voren, bij deze nog maar weer eens, dat door de bank genomen BigData in zijn geheel voor een aanzienlijk en niet te verifiëren deel corrupte data is.
Just a thought.
Data is data, tot zover klopt het maar als we over content (informatie) gaan praten dan wordt het allemaal toch iets minder helder. Koud en warm lijkt me namelijk een semantische differentiaal als we kijken naar mogelijkheden van moderne synthese om datasets te combineren. Tekst is trouwens é6n van de minst gestructureerde vormen als we kijken naar de semantiek, er is steeds meer metadata nodig als we kijken naar de turingtest.
Zeker in een levende taal kunnen woorden niet alleen meerdere betekenissen hebben maar tegenstrijdig aan elkaar worden als ik terugkom op de eerder genoemde semantische differentiaal. Relationele data kenmerkt zich dan ook door het declarieve karakter terwijl idee achter Big Data juist meer imperatief lijkt te zijn, idee van de turingmachine is dan ook niet nieuw. Punt wat de auteur echter lijkt te missen is de vraag aangaande de berekenbaarheid zelf.
De mate van gestructureerd zijn van data wordt voornamelijk bepaald door het vermogen van de mens deze data te interpreteren, de betekenis er van te begrijpen en vervolgens dit begrip om te zetten in een aantal logisch geordende taken zodat een softwareoplossing deze taken kan automatiseren.
Door toegenomen inzicht in semantiek van taal en de technische mogelijkheden dit inzicht te automiseren is men nu in staat bijvoorbeeld sentiment uit tekst te halen. DE vraag is of het resultaat juist is. Mogelijkheden van entimentanalyse zijn nog heel basaal gezien het feit dat de mens in staat is veel meer te doen, zoals interpretatie van de toon, het tempo en context om vervolgens daar een betekenis aan toe te kennen.
Text analytics ontwikkelingen (open source of commercieel) zijn inmiddels zo ver dat de meest waarschijnlijke betekenis van woorden met meerdere betekenissen (homoniemen) uit de context gehaald kan worden.
Ik ben het Ewout eens dat in het geval van tekst niet eenvoudig is, zeker omdat de kwaliteit van tekst (afhankelijk van de bron) laag kan zijn (incompleet, spellingsfouten).
Punt wat ik wilde maken is dat een betekenis toekennen aan gegevens complexe materie kan zijn, maar door de versnelling in (technologische) ontwikkeling de analyse van de meest complexe gegevensstrukturen steeds beter mogelijk wordt en daarmee de gepercipieerde hoeveelheid beschikbare gegevens, naast de intrinsieke groei, de laatste jaren enorm toegenomen is.
Het gaat mijnsinziens voor dit forum te ver om deze discussie richting de fundamenten van de wiskunde te trekken (Turing/Von Neumann) en te beargumenteren of (big) data imperatief/procedureel is, of alle data beslisbaar of zelfs berekenbaar is. Ik nodig de heren graag uit om hier met mij en petit comité verder over te debatteren.
Door menselijke interventie of machine falen wordt data vaak onvolledig of incorrect. Correcte interpretatie van data wordt daarmee ook nog een kwestie van statistiek. Laten we eerst eens een wiskundig juiste definitie van (big) data vastleggen.
“Data is data” zoals Ewout zegt, is in ieder een ware bewering 🙂 Dank voor jullie reaktie.
Het zal ongetwijfeld zo zijn dat complexere gegevensstromen met verbeterende technologie beter, dan wel sneller kunnen worden geanalyseerd, zodanig dat er structuur in te vinden is. De vraag rest dan: wat moeten we met gevonden structuren die ons niets zeggen?
Zo komt er dagelijks een flinke hoeveelheid ruis uit het heelal. Telescopen luisteren daarnaar, slaan het op als data en computers analyseren het, op zoek naar structuur en daarmee naar mogelijke intelligentie buiten onze aardgrenzen. De vraag is dan nog steeds of wij dat soort intelligentie wel kunnen begrijpen. Vooralsnog wordt vrijwel 100% van wat er wordt opgevangen afgedaan als daadwerkelijke, ongestructureerde, ruis.
Dat de data die wij zelf produceren niet ongestructureerd kan zijn, ben ik wel eens met de schrijver, De vraag of die data ook voor iedereen dezelfde of evenveel betekenis heeft, is daarmee dan nog niet beantwoord. De beperking van technologie is dat wij daar wel aan kunnen toevertrouwen structuur of structuren te ontdekken, maar niet de interpretatie daarvan, of in welke mate wij daar betekenis aan toedichten.
Voor de meeste mensen zal de meeste data sowieso abracadabra blijven, met of zonder structuur. Alleen al de onderhavige tekst is voor het gros van de mensheid ombegrijpelijk gepruttel van een nerdy intellectueel.