

In de ruimte tussen het NSA-debacle en de politieke ambitie voor een open overheid ontluikt een gegevenseconomie van e-dienstverlening. Allerlei overheden en publieke instellingen werken hard aan het openstellen van hun interne gegevens voor hergebruik. Met nieuwe concepten, technieken en best practices.
Doel van dat hergebruik kan de toegankelijkheid zijn van de publieke dienstverlening of de efficiëntie van de interne organisatie. Maar ook de ondersteuning van commerciële diensten via slimme sites of apps van derde parijen die worden gevoed door de opengestelde gegevens.
Afgelopen woensdag kon iedereen die te maken heeft met publicatie en hergebruik van open data terecht bij de door Geonovum georganiseerde PiLOD2.0 meeting bij de VU in Amsterdam. Een internationaal gezelschap van open data producenten, app bouwers, onderzoekers, leveranciers van ondersteunende tooling en it-dienstverleners.
Net als vorig jaar moest ik de conclusie trekken dat best practices als Linked Open Data in de geo-wereld al een tijdlang operationeel zijn, maar elders vaak nog in de kinderschoenen staat. Naast de ‘micro’-politieke wil om gegevens te ontsluiten buíten de verantwoordelijke afdeling, is ook de onduidelijkheid wat dit betekent voor gegevensbeheer en it vaak een uitdaging.
Het goede nieuws is: aan die onduidelijkheid en politieke wil valt iets te doen (in die volgorde). Het slechte nieuws: het is geen eenvoudige materie. Daarom dit artikel – het eerste van een serie van drie: (Linked) Open Data for Dummies.
Hyperconnected world
We leven in de tijd van het internet of everything. Alles heeft een chip en is gekoppeld met het internet. Je auto kan meer vertellen over je verkeersovertredingen dan de politie, je horloge meer over je gezondheid dan je huisarts.
In de hyperconnectieve wereld verwacht je van je smartphone dat die niet alleen toegang heeft tot je eigen wearables, smart devices en domotica maar ook tot gegevens van anderen: je sociale en je professionele omgeving, allerlei overheden en openbare instanties en partijen die zaken met je willen doen. Andersom maken ook bedrijven zelf graag gebruik van externe open data om hun business te optimaliseren. Natuurlijk hebben we het dan niet over gegevens op gewone websites, maar over machine-readable open data.
Losser koppelen
Al veertig jaar lang steken organisaties veel energie in het digitaal uitwisselen van gegevens, intern tussen afdelingen en extern tussen ketenpartners. De opkomst van service oriented architecture (soa) en webservices zo’n vijftien jaar geleden maakten dat al een stuk makkelijker. Met soa hoef je de interne werking van een te koppelen applicatie niet meer te kennen, maar kun je uitgaan van afgesproken servicecontracten die het communicatiegedrag van zo’n applicatie op functioneel niveau vastleggen. En webservice standaarden zoals soap definiëren de onderliggende technische protocollen.
Om gegevens uit te kunnen wisselen met een applicatie van een andere afdeling of organisatie moet je dan wel de (web)services van die applicatie kennen. Je hebt dan per service de naam, parameters, pre- en postcondities nodig. Bij de afnemende applicatie moet je vervolgens de nodige analyse- en bouwinspanning doen om die services daadwerkelijk aan te kunnen roepen.
In de context van enterprise application integration (eai) is dat meestal te overzien, maar soms is die inspanning een belangrijke struikelblok voor het realiseren van koppelingen met soap-webservices.
- Als analyse van servicedefinities te tijdrovend is of praktisch verhinderd wordt door ontoereikende documentatie of ontbrekende afstemming met de webservice leverende (it-)organisatie.
- Als het aantal verschillende te koppelen applicaties of datasets te groot is om alle benodigde webservices te kunnen analyseren. Neem bijvoorbeeld een toeristische app die informatie ontsluit over lokale bezienswaardigheden, events en openbaar vervoer. En stel dat die app dat voor alle Europese steden moet doen …
Een ander struikelblok voor traditionele soa-services is de beheerlast voor de aanbiedende applicatie- of gegevensbeheerder.
Soa-services zijn normaal niet bijzonder transparant voor wijzigingen in bedrijfsproces of gegevensstructuur. Het aanbieden van nieuwe of gewijzigde functionaliteit betekent dus meestal een investering in het koppelvlak. En dat geldt dan vaak ook voor de afnemende applicaties of apps. Hetgeen ook weer afdoende releasecoördinatie nodig maakt – en die is (zeker bij open data) niet altijd vanzelfsprekend.
Wie bedenkt dat nog geen één op de duizend apps zich financieel kan bedruipen, kan zich misschien voorstellen dat app-bouwers weinig geduld hebben met ingewikkelde of veranderende servicedefinities.
Kortom, in onze verappte hyperconnectieve wereld vindt gegevensuitwisseling plaats op grotere schaal en met minder ruimte voor wederzijdse afstemming dan vroeger. Daar hebben we meer loose coupling voor nodig dan wat de komst van soa ons bracht.
Interoperabiliteit
Het zal dus niet verbazen dat er – met name op het gebied van open data – nieuwe best practices ontstaan voor gegevensuitwisseling. Die komen tegemoet aan de behoefte aan grotere eenvoud, flexibiliteit en schaalbaarheid van de koppelmogelijkheden (de ‘interoperabiliteit‘) van applicaties en gegevensbestanden.
Nu zijn eenvoud, flexibiliteit en schaalbaarheid ook beoogde kwaliteiten bij traditionele interoperabiliteitspatronen. Welke specifieke voordelen biedende hier besproken ontwikkelingen (Linked Data – en daaraan gerelateerd: Rest) ten opzichte van andere, al langer gebezigde praktijken zoals soap-webservices, cdm-modellen en etl-processen? En in welke gevallen wil je de ene wel gebruiken en de andere niet?
Dit is een vraag die ik vaak heb horen stellen. Door collega’s bij interne vakdiscussies. En door vertegenwoordigers van open data producenten bij de koffie op de PiLOD2.0 bijeenkomst. Hoe overtuig je je eigen (it-)organisatie dat het tijd is om te kijken naar nieuwe, nog onbekende (en onbeminde) mogelijkheden?
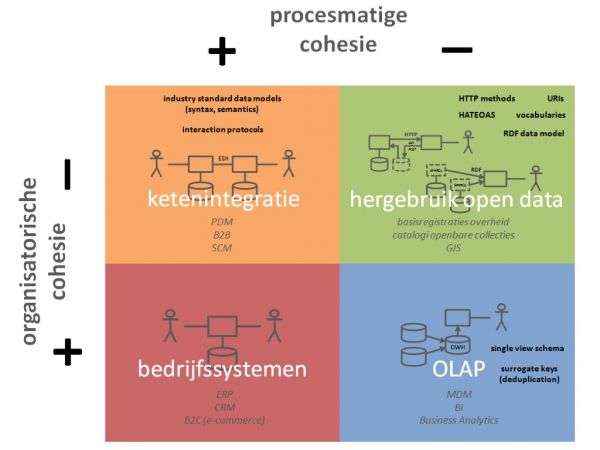
Voor een antwoord op die vragen bespreek ik in mijn volgende artikel vier typeringen van gestructureerde gegevensuitwisseling, uitgezet langs de volgende twee assen (zie ook nevenstaande figuur):
- organisatorische cohesie (betreft het gegevensuitwisseling binnen één (it-)organisatie of tussen meerdere)
- procesmatige cohesie (betreft het gegevensuitwisseling binnen één integraal bedrijfsproces of tussen ontkoppelde processen)
In elk kwadrant bekijken we vervolgens de gebruikte technieken en standaarden die daar één of meer aspecten van interoperabiliteit waarborgen:
- technische interoperabiliteit (compatibiliteit van de syntax van de uitgewisselde gegevens)
- semantische interoperabiliteit (gedeelde interpretatie van de betekenis van de uitgewisselde gegevens)
- proces interoperabiliteit (op elkaar aansluiten van client- en serverprocessen)
- unieke identificatiecodes (gedeelde referenties naar specifieke records / instances)
De conclusie dringt zich op: hoe minder organisatorische en procesmatige cohesie, des te losser de benodigde koppeling voor flexibele en schaalbare interoperabiliteit.
We zullen zien dat Rest-principes en Linked Data-technieken uitermate geschikt zijn om los te koppelen. Met Rest kun je flexibele en schaalbare api’s realiseren door standaard http-functies te gebruiken en door het Hateoas-principe. Linked Data-technieken faciliteren naast api’s ook filetransfer en embedded publicatie van open data. Met de rfd-standaard en door standaard vocabulaires wordt op een flexibele manier syntactische en semantische compatibiliteit geborgd. En zowel Rest als Linked Data gebruikt uri’s als unieke identificatiecodes voor objecten.
Rest en Linked Data zijn daarom ideaal voor publicatie en hergebruik van open data.
Het alternatief blijft natuurlijk om open data in gewone files ter beschikking te stellen. Zelfbeschrijvend of desnoods met externe schemadefinitie. Maar verwacht daarvan geen flexibiliteit of schaalbaarheid. Elke wijziging, toevoeging of aansluiting op andere gegevensbronnen betekent dan weer een investering in de koppelingsinfrastructuur.
Dit en de komende twee artikelen verschenen eerder in een iets andere vorm als blog op de Ordina-website.


