

In onze verappte hyperconnectieve wereld vindt gegevensuitwisseling plaats op grotere schaal en (daardoor) met minder ruimte voor wederzijdse afstemming dan vroeger. De loose coupling die de komst van soa ons bracht is niet meer voldoende.
We hebben andere paradigma’s nodig voor interoperabiliteit. Paradigma’s die tegemoet komen aan de behoefte om snel en simpel informatie over producten, diensten, regels en openbare ruimte ter beschikking te stellen aan specifieke klanten, bepaalde doelgroepen of de hele samenleving. Uiteraard anytime, anywhere, any device. En liefst met zero integration effort.
In een vorig artikel noemde ik Rest en Linked Data als nieuwe best practices voor gegevensuitwisseling voor open data. Welke specifieke voordelen bieden deze ten opzichte van andere, al langer gebezigde praktijken zoals Soap-webservices, cdm-modellen en etl-processen? En in welke gevallen wil je de ene wel gebruiken en de andere niet?
Gestructureerde gegevensuitwisseling
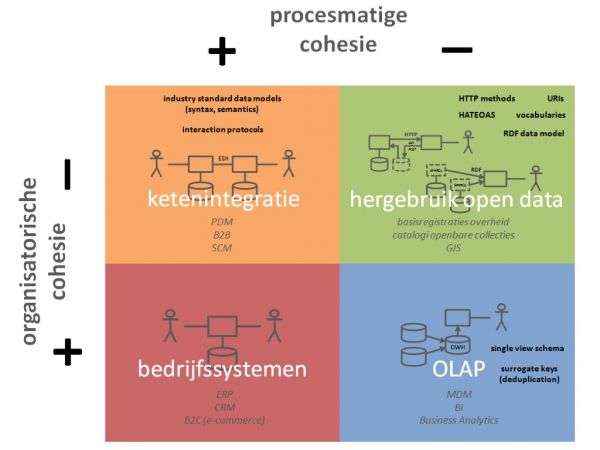
Voor een antwoord op die vragen bekijken we in dit artikel twee dimensies van gestructureerde gegevensuitwisseling:
- organisatorische cohesie (betreft het gegevensuitwisseling binnen één (it-)organisatie of tussen meerdere)
- procesmatige cohesie (betreft het gegevensuitwisseling binnen één integraal bedrijfsproces of tussen ontkoppelde processen)
Dit leidt tot vier typeringen van gegevensuitwisseling. Bij elke typering kijken we naar de gebruikte technieken en standaarden die daar één of meer aspecten van interoperabiliteit waarborgen:
- technische interoperabiliteit (compatibiliteit van de syntax van de uitgewisselde gegevens)
- semantische interoperabiliteit (gedeelde interpretatie van de betekenis van de uitgewisselde gegevens)
- proces interoperabiliteit (op elkaar aansluiten van client- en serverprocessen)
- unieke identificatiecodes (gedeelde referenties naar specifieke records / instances)
Zie het bijgaande figuur. In het kwadrant ‘bedrijfssystemen’ vindt gegevensuitwisseling plaats binnen één systeem of tussen meerdere applicaties van één gebruikersorganisatie (ondersteund door één it-organisatie). Er is sprake van integrale bedrijfsprocessen. Interoperabiliteit is geborgd door de elementaire it-ontwikkelprocessen. In dit kwadrant zijn daarom geen specifieke technieken of standaarden benoemd.
Ketenintegratie
In het kwadrant ‘ketenintegratie’ gaat het om gegevensuitwisseling tussen verschillende organisaties, maar binnen een geïntegreerd proces. Het uitwisselen van de gegevens gebeurt in hetzelfde proces als het vastleggen en het gebruik ervan. Dit proces heeft meestal een duidelijk begin en eind in de tijd. Buiten dat proces worden de vastgelegde gegevens niet uitgewisseld.
Technische en semantische interoperabiliteit wordt geborgd door het gebruik van een standaard datamodel voor de betreffende branche. Proces interoperabiliteit door afspraken over interactieprotocollen. Zowel op technisch nivo (interactiepatronen zoals request/reply, call-back of publish/subscribe) alsook op functioneel nivo (volgorde en afhankelijkheden van bijvoorbeeld customer orders, confirmations, delivery documenten, invoices). Edifact-berichten en Soap-webservices zijn voorbeelden van dit soort afspraken.
Unieke identificatiecodes worden door één centrale applicatie uitgegeven en buiten de context van het betreffende proces niet (her)gebruikt. Daarom is dit interoperabiliteitsaspect hier verder geen aandachtspunt.
Als tussenvorm tussen de kwadranten bedrijfssystemen en ketenintegratie kun je misschien enterprise application integration (eai) noemen. Gegevensuitwisseling vindt hierbij plaats tussen onderdelen van een organisatie – en (ook weer) binnen integrale bedrijfsprocessen. Interoperabiliteit wordt geborgd – parallel aan ketenintegratie – door een common data model (cdm) en interactieprotocollen gebaseerd op rpc of op messaging via soa– en/of eda-architecturen met (web)services en/of esb-koppelingen.
Olap
Olap is on-line analytical processing. Vaak gerealiseerd ‘op’ een datawarehouse (dwh). Het is de basis voor managementrapportages, bi en ba. Operationele applicaties of gegevensbestanden worden hiervoor aan een centraal dwh gekoppeld. Gegevens die in de operationele processen worden vastgelegd, worden vanuit die bronsystemen of -bestanden ook in het dwh geladen (meestal via een etl-proces). Op een onbepaald later moment worden deze gegevens in het dwh ‘hergebruikt’ voor rapportages en analyses in management- en beleidsprocessen. Kortom, de gegevensuitwisseling in dit kwadrant kent een lage procesmatige cohesie.
Het kan bij de gegevensoverdracht naar het dwh voorkomen dat dezelfde personen, producten, aanvragen, dossiers et cetera in verschillende bronsystemen/bestanden andere identificatiecodes hebben. Ook kan het voorkomen dat de betreffende gegevensstructuren in de verschillende bronsystemen/bestanden van elkaar afwijken.
Deze interoperabiliteitsdrempels worden genomen in het etl-proces. Brongegevens worden daar getransformeerd naar de uniforme structuur (single view schema) van het dwh. Bij een ontdubbelingsslag worden surrogate keys toegekend. Eén van de uitdagingen in dit kwadrant is de moeite die het kost om syntactische en semantische wijzigingen of uitbreidingen van de brongegevens telkens over te nemen in de etl- en dwh-structuur.
Hergebruik open data
Open data zijn gestructureerde gegevens die op internet gepubliceerd worden. Traditionele webpagina’s bevatten (behalve opmaak) alleen tekst; bij open data is aan elk gegevenselement ook metadata gekoppeld, zodat het door de afnemer gemakkelijk in een database gestopt kan worden (machine-readable). Belemmeringen voor hergebruik worden tot een minimum beperkt, op allerlei gebied.
- formaat (non-proprietary open standaarden en zoveel mogelijk zelfbeschrijvend; minimaal benodigde kennis van achterliggende datamodellen of protocollen)
- rechten (open licenties: geen beperking op basis van auteurswet, databankenwet of geheimhouding)
- kosten (toegankelijk voor niet meer dan een redelijke kostprijs)
Open data gegevens zijn vastgelegd in een bedrijfsproces dat volledig los kan staan van de publicatie en het hergebruik ervan door de (voor de producent in principe onbekende) afnemers. En meestal zijn de betreffende gegevensbestanden (open datasets) nooit ontworpen voor het betreffende hergebruik.
Het zal duidelijk zijn dat de gegevensuitwisseling in dit kwadrant gekarakteriseerd wordt door zowel lage organisatorische als lage procesmatige cohesie. Voor de interoperabiliteit is het van belang dat de ontsluiting van open datasets maximaal loosely coupled is. Dus eenvoudige en maximaal gestandaardiseerde koppelvlakken. Met als resultaat: schaalbaarheid van aantallen afnemers, en omgekeerd: van aantallen te koppelen datasets. En transparantie van de koppelvlakken voor wijzigingen in de structuur van de datasets.
Er zijn drie verschillende manieren waarop open data wordt uitgewisseld (gepubliceerd en ontsloten).
- embedded (in een traditionele webpagina waarin dan annotations (metadata toevoegingen) zijn opgenomen)
- filetransfer (vergelijkbaar met Edifact-berichten, het downloaden van bestanden of attachments in email)
- api (een vraag-en-antwoord software-laag, meestal via webservices, waardoor afnemers specifieke subsets van de open data kunnen selecteren)
De hierbij gewenste losse koppeling wordt geboden door Rest-principes en Linked Data-technieken. Met Rest kun je schaalbare en flexibele api’s realiseren door het gebruik van standaard http-functies en het Hateoas–principe. Linked Data technieken faciliteren ook de andere genoemde manieren van publicatie en ontsluiting. Met de rdf-standaard en door publicatie van vocabulaires wordt op een flexibele manier syntactische en semantische compatibiliteit geborgd.
Daarnaast gebruiken zowel Rest en Linked Data uri’s als unieke identificatiecodes voor personen, producten, aanvragen, dossiers et cetera. Via het globale dns-mechanisme is zo op een doeltreffende manier het eenduidige wereldwijde auteursrecht belegd voor het toekennen van deze unieke codes (namelijk bij de eigenaar van het betreffende internetdomein).
In een volgend artikel kun je zien hoe deze unique selling points van Rest en Linked Data bijdragen aan de gewenste schaalbaarheid en flexibiliteit van hyperconnected gegevensuitwisseling.
Toekomst
Inmiddels is Rest niet meer weg te denken in de webdevelopment wereld en ik zie de aandacht voor Linked Data bij innovators als BBC en NXP dit jaar brede navolging krijgen bij mainstream adopters. Ook bij de overheid lijkt dat nu in een stroomversnelling te komen. Onder het motto ‘eenmalig registreren, meervoudig gebruiken’ wordt op diverse terreinen met behulp van Linked Data-technieken hard gewerkt aan het openstellen van economisch en bestuurlijk interessante datasets – zoals bijvoorbeeld bij het stelsel van basisregistraties.
De voordelen van deze best practices op het gebied van schaalbaarheid en flexibiliteit zullen ook buiten het open data domein nuttig gebruikt kunnen worden. Zodra kennis van en ervaring met Rest en Linked Data gemeengoed worden binnen de it, zullen ook toepassingsgebieden zoals ketenintintegratie en Oap profiteren van de nieuwe verworvenheden.
Het duurt misschien nog even, maar straks linkt je smartphone net zo makkelijk met je koffiezetapparaat als met je bedrijfsinformatie – en die van al je business partners.



Mmm, @Henri dank voor het voorbeeld, zo te zien biedt de Marketplace evenveel gratis datasets aan als betalende. Dus dat van die ontbrekende business case valt dan wel mee zo te zien. Wel benieuwd waar de grenzen van dat gebruik liggen, wat als de halve wereld elke dag toegang zoekt? (Maar goed, ook eigen infra zal zo z’n grenzen kennen.)
En het wicked problem … tja, goed op de grenzen letten met z’n allen.
Valt beetje in categorie met een bijl kun je ook vervelende dingen doen, maar daarom is het nuttige gebruik niet minder groot. Toch?
Joep, eens.
En wat business cases betreft. Goed om gratis te beginnen, geld vragen of een business model vinden kan altijd nog. Start with simple working systems. Zoals ik schrijf ben ik wel gecharmeerd van het open data model, maar merk ik gewoon niet echt dat het leeft en dan krijg je een catch 22.
Misschien als iemand een “killer” dataset heeft dat de rest ineens vanzelf komt. Ook merk ik bij de overheid dat er wel een paar evangelisten zijn, maar dat er geen natuurlijke stuwing bestaat.
Henri, nee, inderdaad, ik zie (nog) geen grote pull. Ja, catch 22 door ontbreken van (betrouwbaar) aanbod dus weinig vraag dus geen investering in aanbod dus …
Dat gezegd hebbend, ik zie wel dingen bewegen. Tipping point moeilijk te voorspellen, maar ik roep: 2014.
Wat is er geworden van het bekende trio Syntax – Semantiek – Pragmatiek?
Op basis van deze driedeling zou je EA misschien wel als volgt kunnen beschouwen:
Bedrijfsarchitectuur – pragmatisch (Waarom/Waarvoor);
Applicatiearchitectuur – semantisch (Wat/Waarmee);
Technologische architectuur – syntactisch (Hoe/Waaruit).
De achilleshiel van bovenstaand betoog bevindt zich dus precies hier:
> proces interoperabiliteit (op elkaar aansluiten van client- en serverprocessen)
ofwel de plaats waar de pragmatiek – het waarom van de diensten – wordt verwacht.
Nu clients steeds vaker worden opgezet ten behoeve van selfservice, blijkt het procesdenken steeds meer de complicerende factor: het denken in ketens van processen maakt de afhandeling van selfservice nodeloos complex, aangezien selfservice zowel het begin- als het eindpunt van de (vermeende) keten is.
Zie verder mijn reacties op (oa.) Nieuwe industriële revolutie dient zich aan en De revolutie van het vakgebied zonder naam.
Jack, leuk dat je de semiotiek erbij betrekt. Ik zie de essentie van mijn boodschap in die zin als volgt. Met Open Data best practices als REST en Linked Data kunnen we onze interoperabiliteits-inspanningen op een hoger nivo leggen: de pragmatiek. Zoal ik ook uit jou reactie lees zul je het eens zijn dat daar nog voldoende uitdagingen liggen, maar de IT heeft in ieder geval (al jaren) syntactische interoperabiliteitdaar onder de knie, binnenkort (met RESTen Linked Data) ook semantische interoperabiliteit en dan is met de weg geeffend voor focus op pragmatiek.
Juist de ontkoppeling van client- en serverprocessen zou de complexiteit van ketendenken hanteerbaar moeten maken.
Joep, hoewel voor de hand liggend trek je hier iets te snel de conclusie dat ik de semiotiek erbij betrek. Als tekenleer heeft semiotiek mijns inziens niet veel zinnigs te zeggen over betekenissen (semantiek) en doeleinden (pragmatiek). Voor een echte betekenissenleer kan ik de fenomenologie van harte aanbevelen.
Ontkoppeling, zoals mogelijk gemaakt door SOA, heeft inderdaad de belofte van complexiteitsreductie en flexibiliteitsverhoging; een belofte die juist door proces/ketendenken te niet wordt gedaan.