

Tech-reus IBM zet voor de ontwikkeling van nieuwe big data-diensten volop in op Apache Spark. Het heeft zich verbonden aan de ontwikkelaarsgemeenschap rondom de open source software voor opslag, bewerken en analyseren van grote hoeveelheden data in verschillende bestandsformaten.
IBM noemt Spark ‘één van de meest veelbelovende dataprojecten van het komende decennium’ en integreert Spark in het hart van zijn analytics- en commerce-aanbod. De tech-reus meldt dat het op zijn Blue-mix-platform (aanbod van webdiensten) op termijn Spark as a service gaat aanbieden.
IBM brengt zijn SystemML machine learning-technologie in bij de Spark open source-ontwikkelgemeenschap. Het gaat meer dan 3500 onderzoekers en ontwikkelaars inzetten op Spark-gerelateerde projecten in twaalf gespecialiseerde onderzoeklabs. Het bedrijf opent een Spark Technology Center in San Francisco waar innovatieve toepassingen moeten worden ontwikkeld.
Big Blue heeft de ambitie om uitendelijk één miljoen datawetenschappers te trainen in het gebruik van Spark. Dat moet gebeuren door samenwerkingen met organisaties als AMPLab, DataCamp, MetiStream, Galvanize en de Big Data universiteit MOOC.
Tegenhanger Hadoop
IBM ontwikkelt al langer vergelijkbare data-toepassingen op basis van open source platform Hadoop, dat wordt in de markt wordt gezien als tegenhanger van Apache Spark.
IBM deelt niet welk bedrag het reserveert voor de ontwikkelingen rondom Apache Spark. Eerder kondigde het aan 1,2 miljard dollar te investeren in zijn cloud-infrastructuur en 1 miljard in diensten op basis van Watson-technologie.



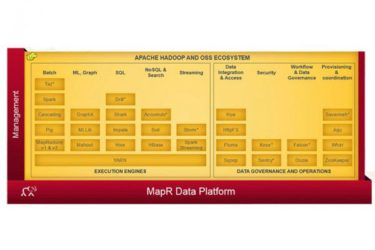

Spark is niet echt een tegenhanger van Hadoop (ook al ziet “de markt” dat zo), maar richt zich een klasse van problemen (interactieve, iteratieve queries) die met Hadoop map-reduce lastig op te lossen zijn. Spark kan in een Hadoop cluster draaien, en maakt gebruik van de Hadoop storage API. Het is dus eerder een uitbreiding van, of aanvulling op Hadoop.
Wel interessant dat IBM dit nu oppakt. Hopelijk leidt dit ook tot meer belangstelling voor de programmeertaal Scala, en functioneel programmeren in het algemeen.