
Verzekeraars hebben heel wat it in huis en daar wordt veel aan getest. Dat vraagt om consistente testdata over de gehele keten. Niet alleen bij verzekeraars, maar bij elke organisatie met data-intensieve it-ketens. Goede testdata krijg je niet cadeau en bestaat uit ‘zelf gemaakte’ testdata in combinatie met productiedata. In deze bijdrage enkele overwegingen daarbij.
Als Nederlanders zijn we de afgelopen weken nogal bezig geweest met onze zorgverzekeringen. Na alle dringende adviezen heb ik m’n zorgverzekering en die van vrouw en kinderen ook maar eens tegen het licht gehouden. Conclusie: eigen risico maximaal (was al zo) en aanvullende verzekeringen minimaal (was ook al zo). Veel goedkoper kan het niet, maar toch schrok ik ook dit jaar weer van de premie.
De zorgverzekeraars schrikken ook omdat we massaal voor dat hogere eigen risico kiezen. Op termijn zullen de premies hierdoor omhoog moeten. Een betere bevestiging dat een maximaal eigen risico niet lucratief is voor de verzekeraar en dus wel voor de verzekerde kunnen we niet hebben. Gemiddeld genomen natuurlijk. Want je zult net zien dat ik dit jaar wel met mijn bumper tegen mijn voorganger en met mijn tanden tegen het stuur knal terwijl ik – conform mijn goede voornemens strikt handsfree te bellen – even niet genoeg op het verkeer let.
Maar dat terzijde, want ik wou het eigenlijk over iets anders hebben: testdata. Momenteel help ik een van de grote Nederlandse zorgverzekeraars om hun testproces verder te stroomlijnen en dan is nadenken over testdata onontkoombaar. De veranderende wetgeving en de competitieve markt zorgen voor een continue stroom van wijzigingen in de complexe administraties van verzekeraars, banken en andere trotse eigenaren van complexe it-landschappen. Snelheid en kosteneffectiviteit zijn daarbij anno 2013 geen luxe meer, maar een kwestie van ’to be or not to be’.
Testdata in de keten
Grip op dit dynamische proces vergt een slimme testaanpak en goede testdata. Goede testdata is consistent en referentieel integer over de gehele keten en voldoet aan de Wet Bescherming Persoonsgegevens. Het creëren en beheren van testdata is nogal een uitdaging. Vooral ook omdat de set productiedata meestal te groot is voor flexibel-testen en ook om privacyredenen niet zonder meer kan worden ingezet. Een discussie die ik vaak hoor is: moeten testers hun testdata zelf maken of kunnen ze productiedata gebruiken? Mijn antwoord is: allebei. Hieronder de redenen waarom.
Er zijn veel redenen om zelf ‘fictieve’ testdata te maken en naar mijn mening zijn dit de belangrijkste: • Nieuwe situaties: Testen van nieuwe functionaliteit vraagt vaak (niet altijd) nieuwe datacombinaties, die in productie nog niet bestaan;
• Structuur en dekking: Systematisch’“Risk & Requirements based testen’ vraagt om een gestructureerd testontwerp waarin de belangrijke functies en datacombinaties systematisch worden gedekt, wat met een onvoorspelbare set productiedata niet lukt;
• Negatief testen: je wilt ook testen dat bedoelde of onbedoelde rare en verboden combinaties netjes worden afgevangen. Negatieve testdata zul je niet of nauwelijks in een productiedump aantreffen.
Waarom testen met productiedata?
Ook hier: er zijn veel goede redenen om productiedata te gebruiken en dit zijn een paar belangrijke:
• Relevantie: de in de praktijk meest voorkomende producten en datacombinaties zijn het meest relevant om grondig te testen;
• Exoten: vreemde combinaties die je wellicht niet had verzonnen maar in de praktijk blijkbaar wel voorkomen pak je mee;
• Polis- en claimhistorie: productiedata bevat een brok historie die slechts met grote moeite en tegen hoge kosten in een testomgeving opgebouwd kunnen worden;
• Snelheid: Je kunt soms (niet altijd) snel een redelijk complete test optuigen met productiedata waarmee je de belangrijkste risico’s waarschijnlijk wel afdekt;
• Volume: Veelal wil je ook testen met grote volumes met een realistische spreiding, ook voor Performance, Load en Stress testen.
Slimme testdata: combinatie
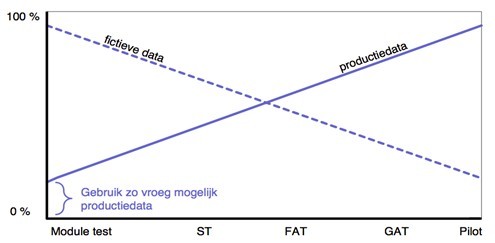
Wat mij betreft is een goede set testdata altijd een combinatie van zelf ontworpen data en productiedata. De ene keer meer van het ene en de andere keer meer van het andere. In zijn algemeenheid geldt: Hoe verder het testen vordert, hoe meer je je omgeving én je data ‘als het ware productie’ wilt hebben. Nevenstaande figuur illustreert dat. Gelukkig zijn er steeds meer goede tools voor testdata management met allerlei voorzieningen voor subsetting en depersonalisatie.
Desondanks blijft het maken en beheren van testdata in een complex itlandschap een uitdaging waarvoor je al je professionele registers moet opentrekken. Maar met ervaring, gevoel voor maatwerk en de business en met inzet van de goede tools komen we steeds verder. Ik draag daar met mijn collega’s met plezier aan bij en verheug me op een creatief 2013, ook in dit opzicht!









Egbert, twee aanvullingen op je artikel:
Een reden om met productie data te testen, is niet alleen testen van de meest voorkomende data en combinaties, maar juist ook de inconsistenties die in productie voorkomen. Onterwerpers en bouwers gaan meestal uit van een zuivere database inhoud, die voldoet aan het database ontwerp. Door fouten die zich hebben voorgedaan in productie (bijv. bij het draaien van een script t.b.v. een functionele aanpassing), kunnen situaties ontstaat waarbij de gegevens in de database niet in alle gevallen voldoen aan de specificaties. Door te testen met productiedata, kunnen problemen die zich voordoen ten gevolge van deze inconsistenties (doordat systemen niet robuust genoeg zijn ontworpen / gebouwd) worden gevonden.
Als je “lukraak” gaat testen met productiedata, loop je alsnog de kans de variatie m.b.t. data en combinaties niet volledig te raken. Een techniek die daarbij kan helpen, is met slimme queries (bijna op een data mining achtige manier) verschillende variaties uit de productiedata te selecteren / filteren. Door die zorgvuldig geselecteerde testgevallen als uitgangspunt voor de testen te nemen, kun je de dekkingsgraad aanzienlijk verhogen.
Hallo Pepijn,
Goed punt en die inconsistenties vallen wat mij betreft onder de “Exoten” die ik beschrijf als “vreemde combinaties die je wellicht niet had verzonnen maar in de praktijk blijkbaar wel voorkomen”.
En inderdaad: selecties van productiedata gebruiken als vertrekpunt en die zelf aanpassen en uitbreiden is een slimme manier om beide benaderingen te combineren.